The metric M3 tracks the structure of the traffic at root servers. This is done by analyzing samples of traffic from the ICANN Managed Root Server (IMRS). IMRS use anycast addressing to direct the service to hundreds of servers distributed around the world. Each day, our partners process 2-minute traffic samples from each of these servers. To avoid time-of-day bias, the time to start each server's sampling is picked at random, using independent random draws for each server. Our partners then send us the summary data for each sample, which are aggregated at the end of the month into one big summary file. The M3 metrics are computed from this summary. There are two sets of metrics:
In theory, the root traffic should just contain requests by recursive resolvers for the NS records of TLD servers. Those requests should be cached for the time to live of the records, which means that the same resolvers should only repeat the same query after the time to live of the previous expires, or maybe if it is almost ready to expire. In practice, our analysis so far shows that the traffic from the root does not meet this theoretical explanation: a large part of the traffic is composed of requests for names that do not correspond to registered TLD; and, a large fraction of the requests to regular TLD are repeated at short intervals, much lower than the TTL. This leads to the definition the metrics M3, which are in fact 3 metrics:
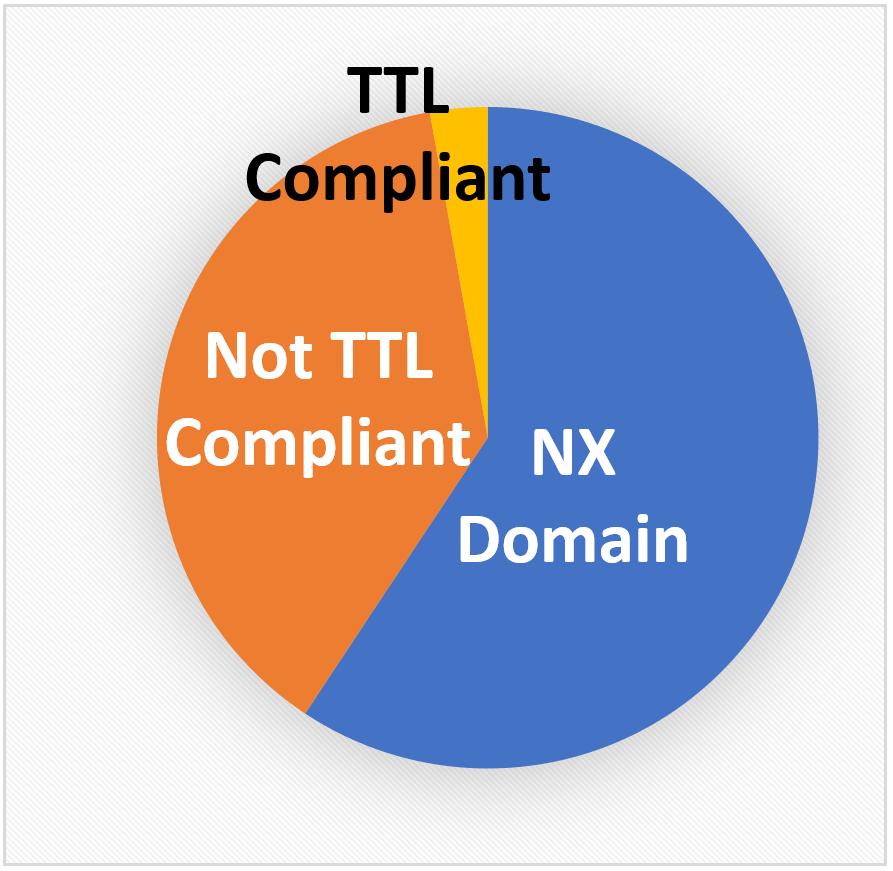
The pie-chart above shows the division of traffic between "NX Domain" (M3.1), "Not TTL Compliant" (M3.2) and "TTL Compliant", defined as: 100% - M3.1 - M3.2.
The name leakage at the root is measured by the M3.3 metrics. Earlier measurements showed that this leakage corresponds to several classes of name. We want to measure the evolution of this leakage over time with M3.3, which is composed of 4 metrics, M3.3.1 to M3.3.4.
The first class of leaks corresponds to special use domain names such as for example “.LOCAL”, reserved by the IETF according to RFC 6761, and recorded by IANA in the Special Use Domain Names registry . For each of the special use domain name, the tools will compute:
The second class of leaks corresponds to commonly configured “unregistered” strings, such as for example “.HOME”. These strings are typically configured in private networks, which their administrators believed to be isolated from the Internet. However, experience shows that such isolation is imperfect. The tools will find out which of these unregistered strings appear most frequently in the traces, and will compute:
We also observe that a large fraction of the leaks is caused by “made up” names. Some of these appear to be the output of Domain Generation Algorithms (DGA). Some are generated by software trying to assess local connectivity to the DNS by sending a query to the root server; doing so with a newly generated DGA name increases the probability that the query will be sent all the way to the root. Other may be the result of test tools, attack tools, configuration errors, or plain software bugs. The tools will attempt to characterize use of such patterns by computing:
Finally, we will also measure the fraction of leaks that are not explained by M3.3.1, M3.3.2 or M3.3.3:
This definition assumes that there is no double-counting, and that for example a given string cannot be accounted both as an individual string in M3.3.2, and as part of a pattern in M3.3.3.
The current values of the metrics is available here.
We can deduce from the traffic seen at root servers some characteristics of the resolvers that are directly accessing the root such as whether resolvers use extended DNS (M3.4.1), what EDNS options they use (M3.4.2), whether they set the DNSSEC OK bit in queries (M3.5), and whether they appear to enforce QName Minimization (M3.6)
All these metrics are computed as a ratio of number of resolvers using the feature versus total number of resolvers. We identify resolvers by their IP address, we compute the number of IP addresses for which the feature is present, and we divide by the total number of IP addresses to obtain the ratio. We will count the number of IP addresses in each sample of root traffic analyzed for a month, and we will sum the number of IP addresses across all samples before computing the ratios.
In order to reduce the noise in the measurement, we only perform these statistics on valid queries, and we ignore IP addresses from which we only receive invalid queries.
For each IP address found, we perform the following computations:
We understand that performing statistics per IP address will lead to imprecisions if multiple resolvers share the same IP address, which happens if they are behind the same NAT. We will attempt in the future to quantify this imprecision.